
type
status
date
slug
summary
tags
category
icon
password
fullWidth
fullWidth
目标导向行为规划(GOAP)知识梳理
【前置知识】A*搜索算法:游戏算法-A*搜索算法知识梳理和通用框架 | 白雪团子
传统AI决策方法的局限
现有游戏AI架构(如有限状态机/行为树/分层任务网络)通过预设的决策结构实现行为响应,其智能表现受限于三个核心要素:
- 状态切换机制:有限状态机依赖开发者定义的状态转移规则
- 节点连接逻辑:行为树需要预构建树的结构
- 任务分解方案:分层任务网络要求预先设计复合任务分解方式
这些方法在扩展性方面存在天然瓶颈——新增行为需要重新调整结构,难以实现"即插即用"的行为扩展。
GOAP的革新设计理念
目标导向行为规划(Goal-Oriented Action Planning)通过状态空间搜索实现了:
- 解耦设计:设计者只需定义原子动作及其作用效果
- 动态规划:系统使用搜索算法(如Astar)自动生成最优动作序列
- 灵活扩展:新增动作无需修改现有决策结构
GOAP的运行逻辑
1. 定义状态和动作
- 状态:由一系列属性构成(如“有枪”“有火”)。
- 动作:改变状态的操作(如“烹饪”)。
- 前提条件:执行动作所需的条件(如“有食物”)。
2. 初始状态和目标状态
- 初始状态:智能体的当前状态(如“饿”)。
- 目标状态:智能体希望达到的状态(如“饱”)。
3. 搜索和规划
- 图搜索:将状态和动作建模为图,用搜索算法(如A*)找到从初始状态到目标状态的最短路径。
- 动作序列:得到一系列动作,按顺序执行可达到目标。
- 动态调整:若状态变化,重新规划。
5. 总结
GOAP将问题抽象为图:
- 节点:表示状态(如“饿”、“饱”、“有食物”)。
- 边:表示动作(如“吃饭”),边的连通性是动作执行的前提条件。
- 目标:找到从初始状态(起点)到目标状态(终点)的路径。
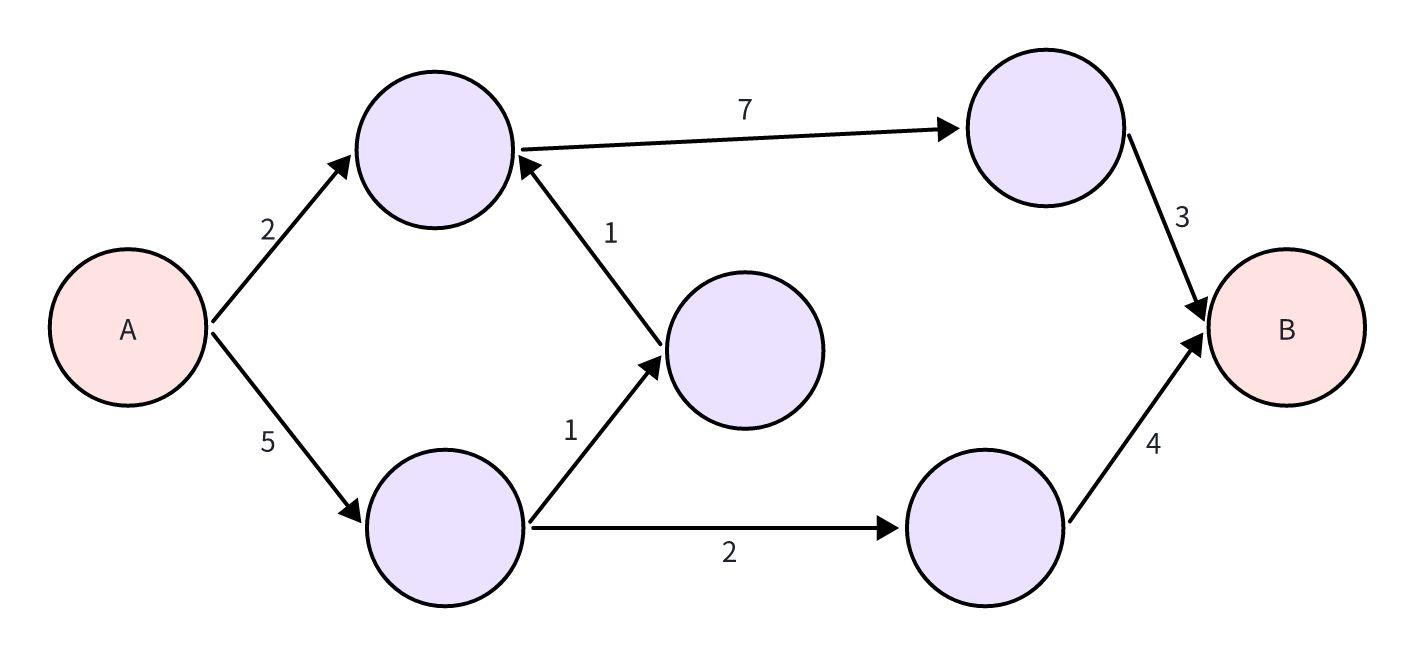
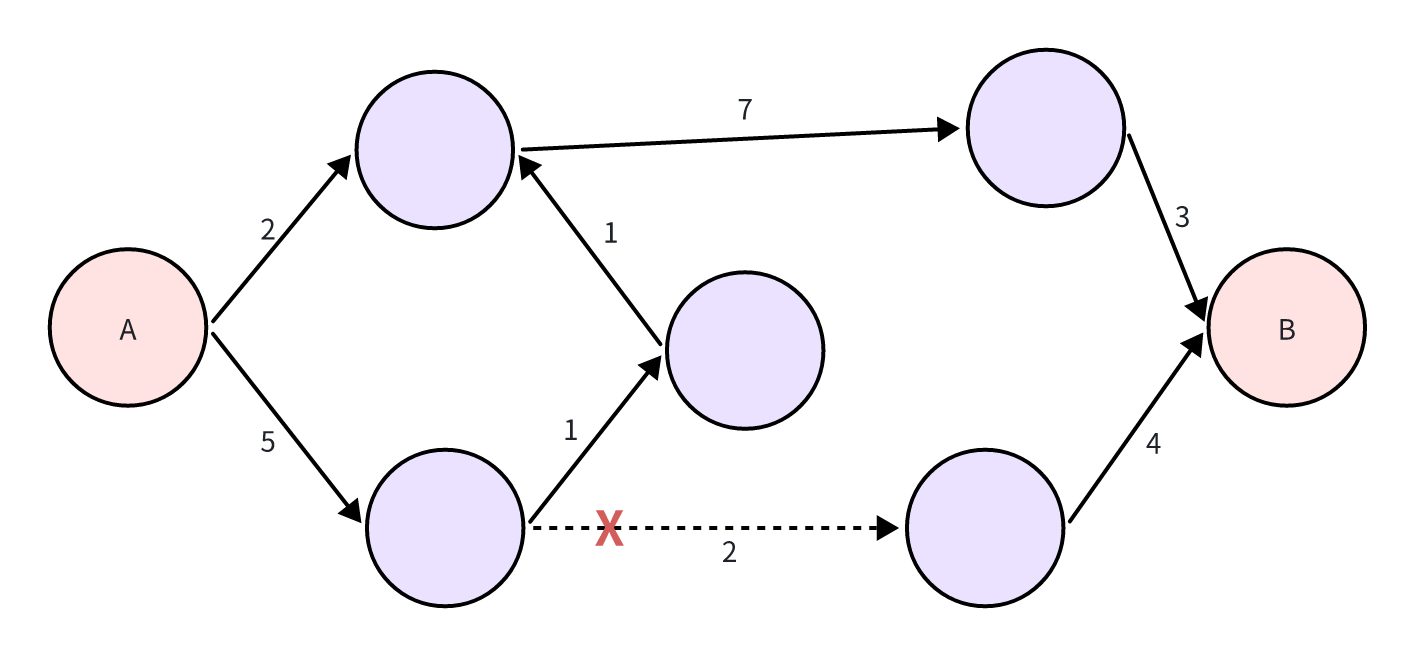
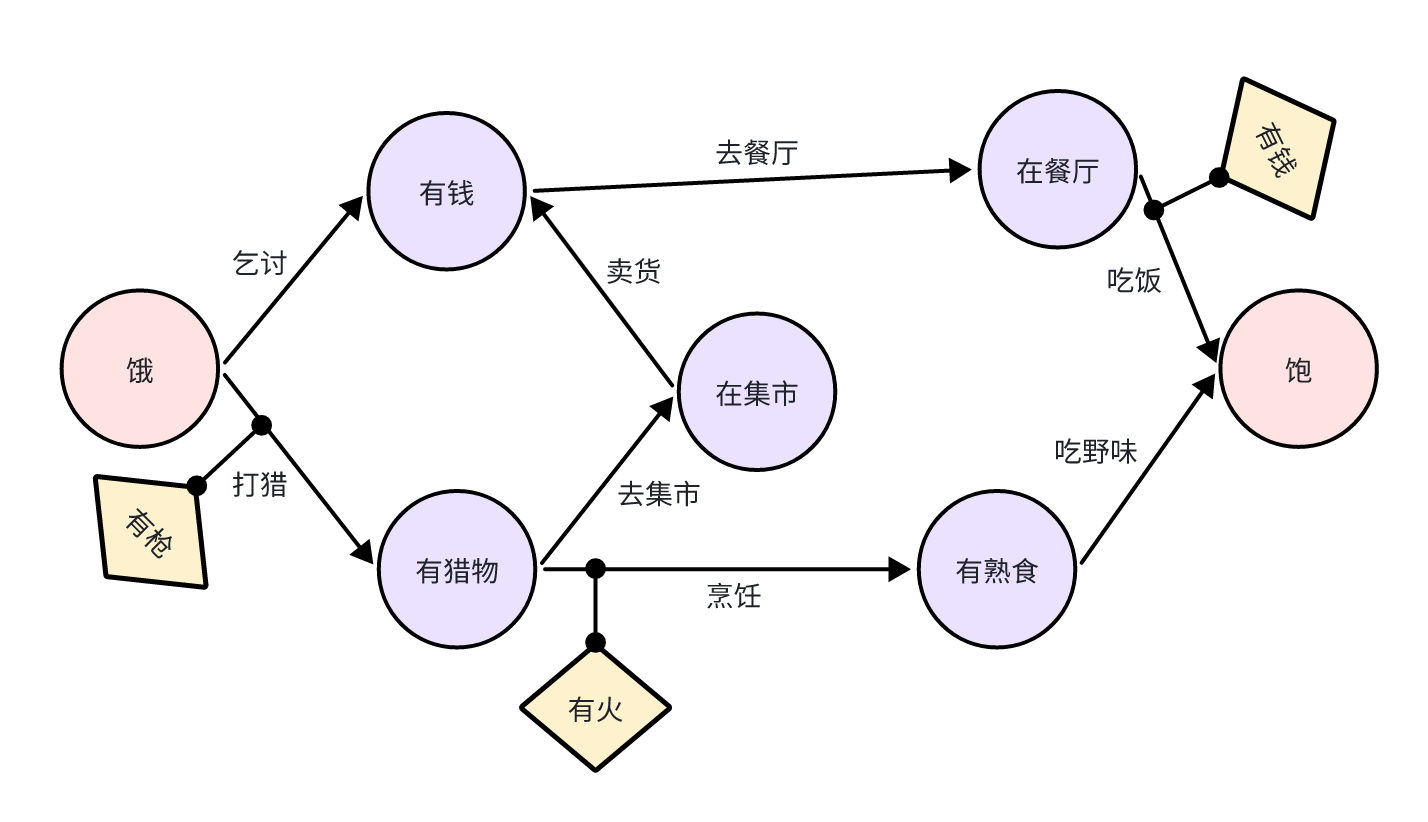
目标导向行为规划(GOAP)通用框架
GOAP的代码实现
状态池(StatePool)
1. StateKey 枚举
定义了状态的键,每个键对应一个二进制位,方便通过位运算进行状态管理。
- 示例:
HasLeg = 1 << 0表示0000 0001,IsWalking = 1 << 1表示0000 0010。
2. GoapStatePool 类
管理状态实例的池,确保相同的状态只存在一个实例。
- 单例模式:通过
Instance属性获取唯一的GoapStatePool实例。
- 状态池:使用
Dictionary<int, GoapWorldState>存储状态实例,键为状态的哈希值。
GetOrCreateState:根据传入的状态数据,计算哈希值,如果池中已存在该状态则返回,否则创建新状态并存入池中。
CalculateHash:通过位运算计算状态的哈希值,确保相同状态生成相同的哈希。
世界状态(WorldState)
表示游戏世界中的状态,每个状态实例包含一组键值对。
- 状态存储:使用
Dictionary<StateKey, bool>存储状态条件,键为StateKey枚举类型,值为布尔类型,表示该状态条件是否满足,可理解为搜索空间图的边是否连通的阀门。
- 邻居节点:通过
Neighbors属性存储当前状态的邻居状态及其连接代价(动作代价)。
- 状态操作:提供方法用于设置、获取状态值,以及计算状态之间的距离(启发式函数)。
动作(Action)
GoapAction 类表示一个动作,包含动作的前提条件和效果;每个动作在执行前需要检查前提条件是否满足,执行后会修改世界状态。
1. MetCondition
public bool MetCondition(GoapWorldState worldState)
- 作用:检查当前世界状态是否满足动作的前提条件。
- 实现:遍历
PrecondState,与传入的GoapWorldState进行比较,如果所有条件都满足则返回true,否则返回false。
2. EffectOnRun
public void EffectOnRun(GoapWorldState worldState)
- 作用:将动作的效果应用到传入的世界状态中。
- 实现:遍历
EffectState,更新GoapWorldState中的对应状态值。
3. SetPrecond
public GoapAction SetPrecond(StateKey key, bool value)
- 作用:设置动作的前提条件;返回当前对象,支持链式调用。
- 示例:
SetPrecond(StateKey.HasLeg, true);。
4. SetEffect
public GoapAction SetEffect(StateKey key, bool value)
- 作用: 设置动作的效果;返回当前对象,支持链式调用。
- 示例:
SetEffect(StateKey.IsWalking, true);。
GoapActionSet 类用于管理一组动作(
GoapAction),并提供动作的添加、查询和状态转换功能。它通过一个有向图结构(MyGraph)来维护动作之间的关系,其中图的节点是世界状态(GoapWorldState),图的边是动作名称。1. 索引器
public GoapAction this[string name]
- 作用:通过动作名称获取对应的动作。
- 示例:
GoapAction action = actionSet["Walk"];。
2. HasAction
public bool HasAction(string name)
- 作用:检查动作集中是否存在指定名称的动作;如果存在则返回
true,否则返回false。
- 示例:
bool hasWalk = actionSet.HasAction("Walk");。
3. AddAction
public GoapActionSet AddAction(string actionName, GoapAction newAction)
- 作用:将动作添加到动作集中,并更新图结构以反映动作的前提条件和执行效果。
- 实现:
- 将动作名称和动作对象添加到
actionSet字典中。 - 使用
GoapStatePool获取或创建动作的前提条件和效果状态。 - 在图中添加前提条件和执行效果状态作为节点,并添加动作名称作为边。
- 返回当前对象,支持链式调用。
- 示例:
4. GetTransAction
public string GetTransAction(GoapWorldState from, GoapWorldState to)
- 作用:获取从一个世界状态转换到另一个世界状态的动作名称。
- 实现:在图中查找从
from状态到to状态的边,并返回动作名称;如果存在多条边,默认返回第一条。
- 示例:
string actionName = actionSet.GetTransAction(fromState, toState);。
智能体(Agent)
GoapAgent 类是一个代理器,用于整合管理世界状态、动作集、规划路径以及动作的执行。它通过 A* 搜索算法找到从当前状态到目标状态的动作序列,并依次执行这些动作。
核心成员
- _curWorldState:当前的世界状态。
- _actionSet:动作集,包含所有可用的动作。
- goapAStar:A* 搜索器,用于规划从当前状态到目标状态的动作序列。
- _actionFuncs:动作名称到动作函数的映射。
- _actionPlan:规划出的动作序列队列。
- _statePath:规划出的状态路径栈。
- curState:当前动作的执行结果(
Failure、Success或Running)。
- canContinue:是否能够继续执行动作序列。
- curAction:当前执行的动作。
- curActionFunc:当前运行的动作函数。
方法
1. SetActionFunc
public void SetActionFunc(string actionName, Func func)
- 作用:为动作名称设置对应的动作函数;只有在动作集中存在该动作时,才会设置动作函数。
- 参数:
actionName:动作名称。func:动作函数,返回EStatus类型的结果。
2. RunPlan
public void RunPlan(GoapWorldState curWorldState, GoapWorldState goal)
- 作用:规划从当前状态到目标状态的动作序列,并执行动作。
- 参数:
curWorldState:当前的世界状态。goal:目标的世界状态。
- 实现:
- 如果当前动作的执行结果为
Failure,则重新规划动作序列。 - 如果当前动作的执行结果为
Success,则将动作的效果应用到当前世界状态。 - 如果当前动作的执行结果不是
Running,则从动作序列中取出下一个动作并执行。 - 如果动作的前提条件满足,则执行动作函数并更新当前状态;否则,将当前状态设置为
Failure。
GOAP的改进方案
引入动作代价
经测试,对于有向无权图,存在多条等价路径时,A*算法每次都会找到同一条路:
- 节点的邻居是通过
GetSuccessors方法获取的。
- 加入动作(边)的顺序是固定的,导致邻居节点的顺序是固定的,A* 会优先选择第一个满足条件的节点,从而每次找到的路径相同。
因此期望引入动作代价,使GOAP的搜索空间成为一张有向有权图,来进一步精细化控制智能体的行为,使之倾向于选择动作代价更小的路径,显得更“聪明”。
1. 在GoapAction中引入动作代价
2. 在GoapWorldState中引入邻居节点和连接代价
3. 在GoapActionSet的AddAction中构建邻居
添加动作时构建
precondState 的 Neighbors 字典,并把邻居节点 effectState 作为键,边代价 Cost 作为值加入字典。4. 获取后继状态时更新SelfCost
在
GetSuccessors 接口中更新邻居节点的 SelfCost 属性,属性值为动作代价(边长),以便 AstarSearcher 在更新开放列表和关闭列表时使用该属性来更新总代价。引入值类型的状态
1. 修改状态储存形式
将
GoapAgent 中的状态存储从Dictionary<StateKey, bool>改为Dictionary<StateKey, object>,支持多种值类型(如int、float、string等)。RunPlan 也要相应修改,MetCondition
2. 引入全局比较函数字典
在
GoapWorldState 中引入_stateComparers,存储每个StateKey对应的比较函数,支持自定义的状态值转换逻辑,将值类型转换成bool类型。为什么要转换成bool类型?
因为GOAP的搜索空间是基于有向图的,每条边都需要阀门来控制它的连通性(即动作执行条件是否满足),因此最终的状态必须用bool值来表示。
2. 引入状态转换函数
状态转换函数
ConvertStateData 通过全局字典 _stateComparers 调用自定义的比较函数,将值类型转换为布尔类型。3. 引入效果函数用于改变值类型的状态
新增
Effect 字典,存储动作的效果函数;在 EffectOnRun 中调用效果函数修改世界状态,支持对值类型状态的动态更新。MetConfition 也要相应修改,将值类型状态转换成bool类型再和 PrecondState 作比较。GoapAgent 的 RunPlan 中应用直接应用动作效果于当前状态。功能测试
创建一个Csharp脚本
Test.cs ,挂载在场景的游戏物体上。使用代码构建的GOAP图如下所示:
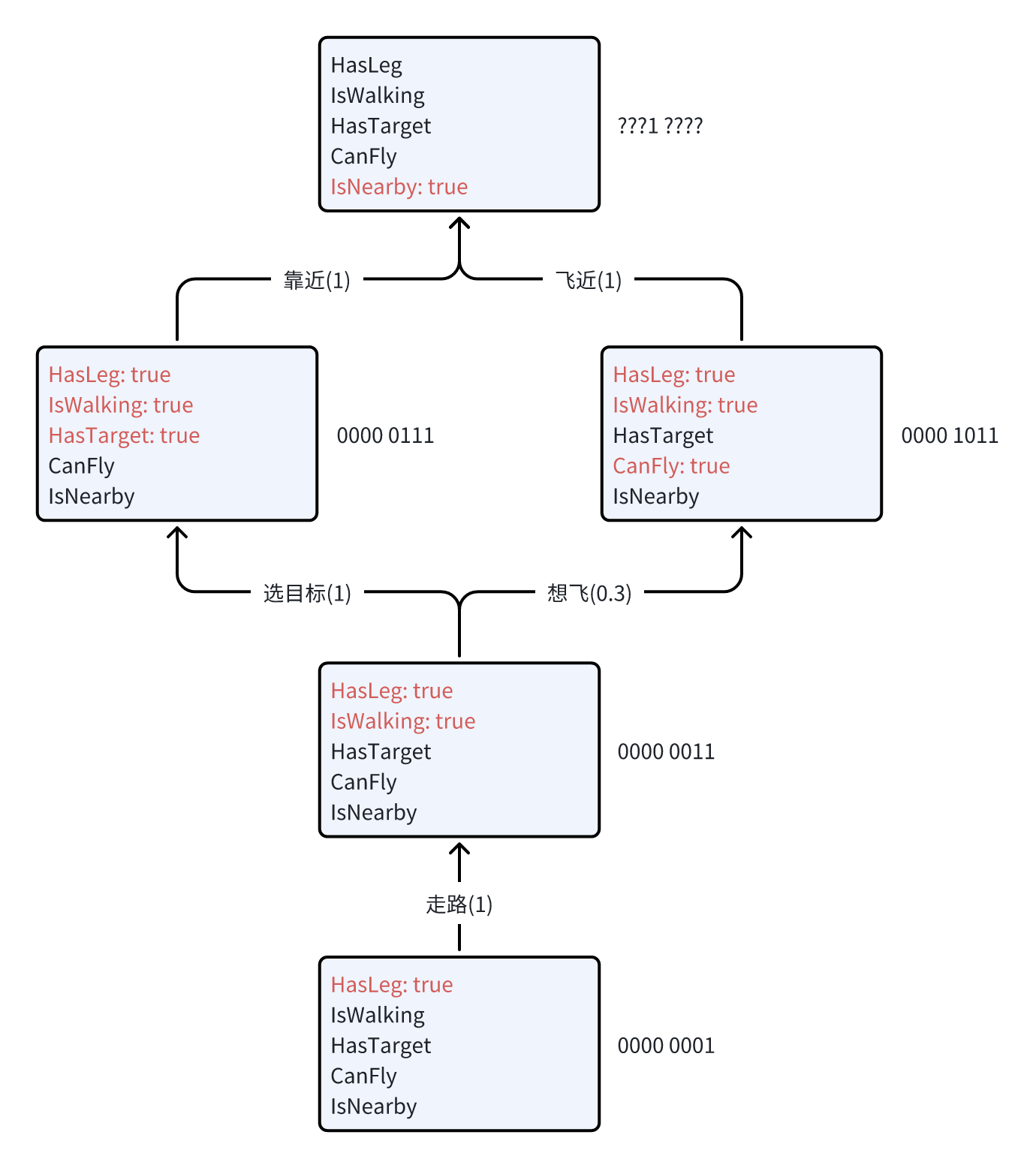
运行测试脚本后,控制台输出如下:
结果分析:
1. 动作序列规划
- 有两条路可走:走 → 选目标 → 靠近、走 → 想飞 → 飞近;GOAP 系统选择了第二条路,因为这一序列的代价更小(“想飞”的代价从 1 修改为 0.3)。
2. 值类型状态的支持和动态修改
CanFly状态从"不能飞行"动态修改为"可以飞行",IsNearby状态从 50 动态修改为 5,并分别通过比较函数转换为布尔类型。
- Author:Yuki
- URL:http://shirakoko.xyz/article/goap
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts










